Stress-Strain Diagram (proportional limit, Elastic limit, Yield point, Ultimate point, Fracture point)
- Based on % elongation, Ductile and brittle materials are categories % Elongation = (Final length – Initial length / Initial length ) * 100 %
- If % Elongation is less than 5 % then we can say the material is brittle. If % Elongation is range between 5 % to 15 % then the material is an intermediate ductile material. If % Elongation is greater than 15 %, the material is called “Ductile material”
- In brittle material, there is no plastic deformation or very negligible plastic deformation.
- Another very general method to identify the material as ductile or brittle is by examining the fracture surface. Generally, ductile material is failed by cup-cone phenomena while brittle material is failed by a flat surface. So, based on the fracture surface we can also achieve little idea about the type of material that is ductile or brittle.
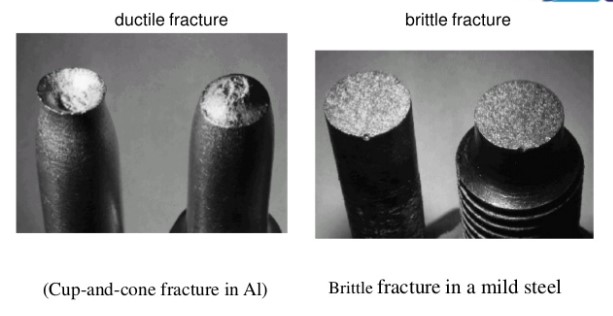
- FIG – 1
-
- Material’s elongation test or tensile test is done on ‘Dogbone specimen or Dumble shape specimen’ by UTM (Universal testing machine). The gradually tensile load is applied on the specimen and stresses induced in gauge length are plotted on the stress-strain diagram i.e. stress-strain diagram indicates the value of strain & corresponding stress which is induced in the gauge length of the specimen.
- The shape of a stress-strain diagram depends on two things (1) which type of material you tested (2) which kind of stress or load you applied during testing. It may be tensile or compression and according to that graph, shape will be plotted.
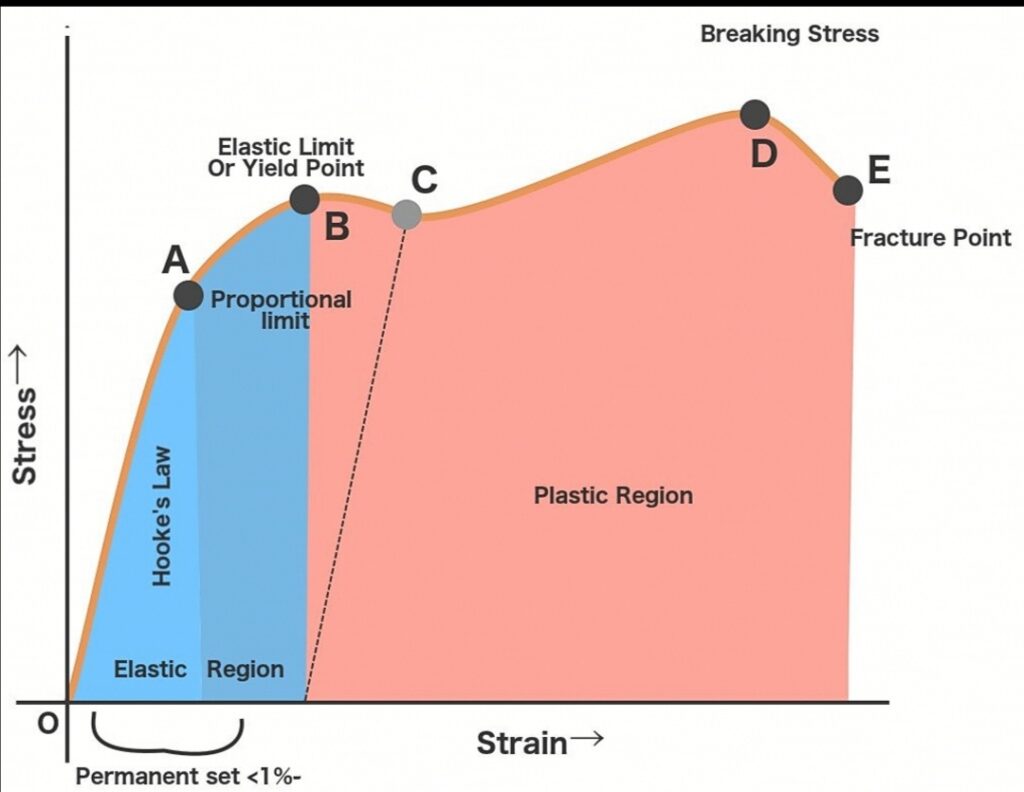
- FIG – 2
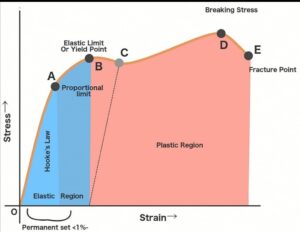
- The above image shows the stress-strain diagram of mild steel. There are many different points or regions located on the stress-strain diagram explain below
1. Proportional limit
2. Elastic limit
· Upper Yield point
· Lower Yield point
5. Fracture point
People also search – Types Of Welding Position (Flat, Horizontal, Vertical, Overhead,1G 2G 3G 4G 5G 6G welding position)
Proportional limit
It is the limit at which material follows Hook’s law and represents the maximum value of stress at which the stress-strain diagram is linear and within this limit, the ratio of stress to strain gives a proportional constant called Young’s modulus. The line OA on a stress-strain diagram shows a proportional limit.
Elastic limit
It is a limit up to which material (specimen) behaves elastically. However, the curve is not shown as linear between the elastic limit & proportional limit but the material is still elastic and if the load is removed within the elastic limit, the specimen will return to its original dimension. After this limit, plastic deformation will start in the specimen and the specimen will deform permanently. The line AB on a diagram shows an elastic limit.
Yield point
At the yield point, the material starts to deform plastically, and after the yield, point material deforms permanently. There are two yield points (1) Upper yield point (2) Lower yield point.
On a diagram, Point B is the upper yield point and point C is the lower yield point. The stress at the yield point is called yield strength.
Lower yield point
The lower yield point is considered as strength criteria for ductile material because it is clearly seen from the stress-strain diagram that above any point of lower yield point, there will always be some yielding occurred. So the stress value at point C (see the above diagram) must require to be considered while designing to maintain yielding or maintain the material deformation up to the elastic limit. That’s why the Designer takes the value of the lower yield strength.
For some materials (Mostly brittle material), the value of yield stress or yield point is not clearly visible or not able to identify on a stress-strain diagram of that material. In this case, we use the 0.2 % offset method to determine yield stress. Draw a line parallel to the linear portion (Proportional limit) of the curve on the X-axis at a strain value of 0.002. The second endpoint which intersects the stress-strain curve corresponding value of stress at the Y-axis is noted as ‘Yield strength’
There are many other properties understood from the stress-strain diagrams like plasticity, toughness, stiffness, resilience, proof resilience, ductility, Brittleness, etc.
Ultimate point
The ultimate points indicate the maximum stress that a material can withstand before failure. The corresponding stress value is called ‘Ultimate strength’. After this point, failure occurs.
Necking is started at the ultimate point and stress reduces after the ultimate point significantly due to necking. Specimens become thinner and thinner. The value of the internal resisting force will continuously decrease. That is why stress is continuously reduced after an ultimate point. Point D on a diagram is the ultimate point.
Fracture point
It is a point at which the specimen will completely fail and the specimen will break into two pieces. Point D on a diagram is the ultimate point.